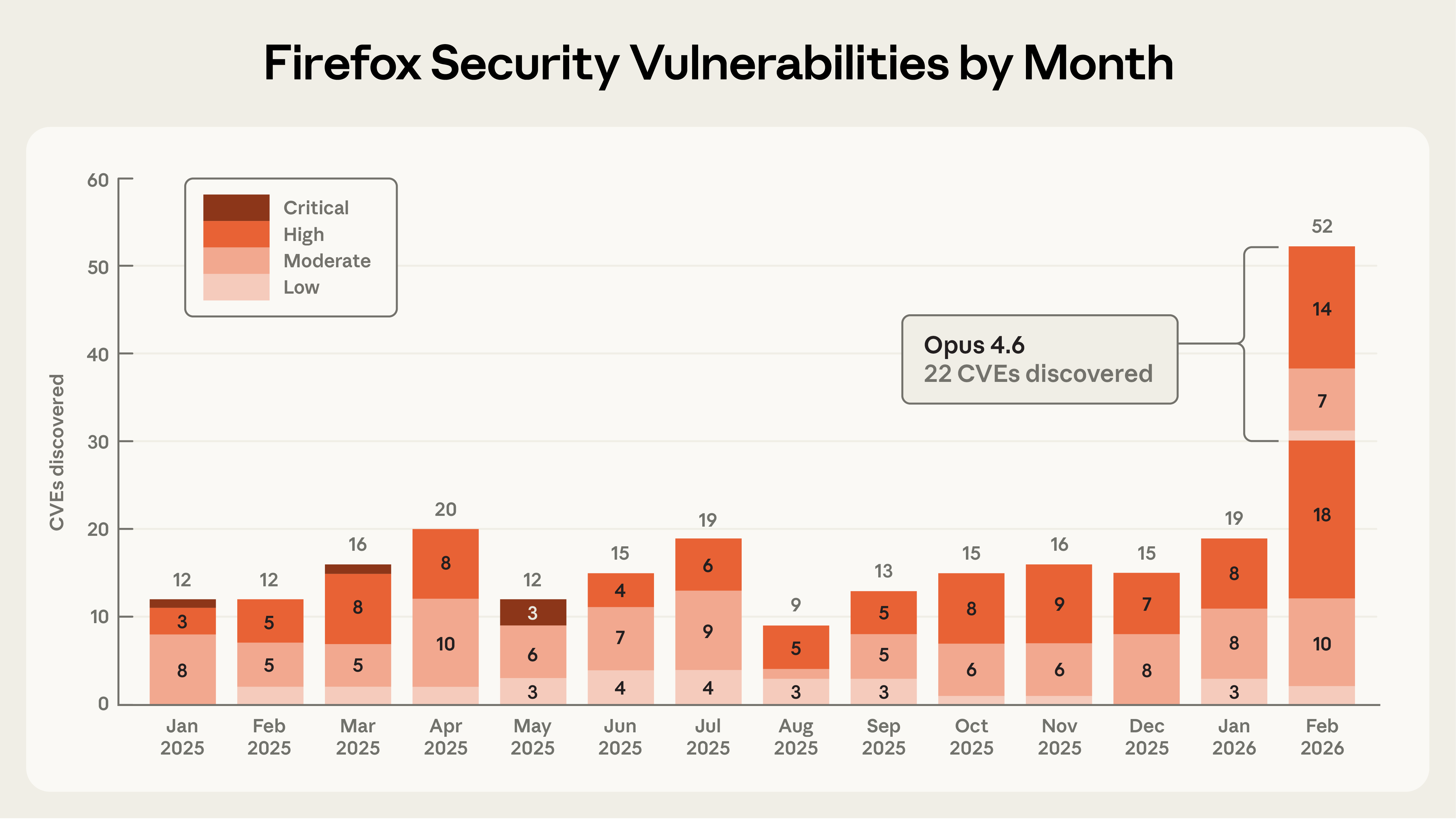
Claude Opus 4.6 在两周内发现了 Firefox 的 22 个漏洞,其中 14 个为高危漏洞,AI 正在以前所未有的速度提升网络安全。
AI 模型现在能够独立识别复杂软件中的高危漏洞。正如 Anthropic 此前记录的那样,Claude 在经过充分测试的开源软件中发现了 500 多个 zero-day 漏洞(软件维护者未知的安全缺陷)。
在本文中,Anthropic 分享了与 Mozilla 研究人员合作的详细信息:Claude Opus 4.6 在两周内发现了 22 个漏洞。其中,Mozilla 将 14 个评定为高危漏洞——几乎占 2025 年所有已修复的高危 Firefox 漏洞的五分之一。换言之:AI 正在使检测严重安全漏洞的速度大幅提升。
作为此次合作的一部分,Mozilla 接收了大量来自 Anthropic 的报告,帮助 Anthropic 理解哪些类型的发现值得提交 bug 报告,并在 Firefox 148.0 中向数亿用户推送了修复补丁。
从模型评估到安全合作
2025 年底,Anthropic 注意到 Opus 4.5 即将解决 CyberGym(一个测试 LLM 能否复现已知安全漏洞的基准测试)中的所有任务。团队想要构建一个更难、更真实的评估,于是选择了 Firefox——它既是一个复杂的代码库,也是世界上测试最充分、最安全的开源项目之一。
发现过程
- 复现已知 CVE:首先使用 Claude 在 Firefox 旧版本中查找先前已识别的 CVE。令人惊讶的是,Opus 4.6 能够复现这些历史 CVE 的很高比例
- 寻找新漏洞:然后让 Claude 在 Firefox 当前版本中寻找全新漏洞——这些漏洞按定义之前从未被报告过
- 首个发现:仅经过20 分钟的探索,Claude Opus 4.6 就报告发现了 JavaScript 引擎中的一个 Use After Free 漏洞(一种可能允许攻击者用任意恶意内容覆盖数据的内存漏洞)
- 批量发现:在验证和提交第一个漏洞的过程中,Claude 已经发现了另外 50 多个独特的崩溃输入
最终,Anthropic 扫描了近 6,000 个 C++ 文件,共提交了 112 份独立报告。大多数问题已在 Firefox 148 中修复,其余将在即将发布的版本中修复。
从发现漏洞到编写原始 Exploit
为了衡量 Claude 网络安全能力的上限,Anthropic 还开发了一项新的评估,测试 Claude 是否能够利用其发现的漏洞编写 exploit。
关键发现:
- 花费约 $4,000 的 API 费用,运行了数百次测试
- Opus 4.6 仅在两个案例中成功将漏洞转化为 exploit
- 结论一:Claude 发现漏洞的能力远强于利用漏洞的能力
- 结论二:识别漏洞的成本比创建 exploit 便宜一个数量级
重要说明:Claude 编写的 exploit 仅在移除了部分安全功能的测试环境中有效。Firefox 的"纵深防御"机制(特别是 sandbox)在实际环境中能有效缓解这类 exploit。
AI 网络安全的下一步
这些 AI 驱动的 exploit 开发的早期迹象,强调了加速"发现-修复"流程对防御者的重要性。Anthropic 分享了几项技术和流程最佳实践,并在开发"patching agents"——使用 LLM 来开发和验证 bug 修复——方面取得了进展。
编辑点评
这篇文章堪称 AI 安全研究的标杆案例。20 分钟发现第一个高危漏洞、两周内找到 22 个漏洞——这些数字令人震撼,但更重要的是 Anthropic 与 Mozilla 合作的方式。他们不是闭门造车,而是与上游维护者建立了透明的协作流程,确保发现能转化为实际的安全修复。同样值得关注的是"攻防不对称"的发现:Claude 发现漏洞的能力远强于利用漏洞的能力,这意味着 AI 在当前阶段对防守方的价值更大。花 $4,000 扫描 6,000 个文件的成本效率,意味着 AI 驱动的安全审计即将成为每个大型开源项目的标配。


