Anthropic 发布 Claude Sonnet 4.6——迄今最强 Sonnet 模型,编码、计算机使用、长上下文推理全面升级,并支持百万 token 上下文窗口。
Claude Sonnet 4.6 是 Anthropic 迄今最强大的 Sonnet 模型,在编码、计算机使用(Computer Use)、长上下文推理、Agent 规划、知识工作和设计等技能上实现了全面升级。同时,Sonnet 4.6 还以 beta 形式提供了 100 万 token 上下文窗口。
定价与前代 Sonnet 4.5 相同,起步价为每百万 token $3(输入)/ $15(输出)。
编码能力大幅提升
Sonnet 4.6 为更多用户带来了显著提升的编码能力。在一致性、指令遵循等方面的改进让早期用户以压倒性优势偏好 Sonnet 4.6。他们甚至常常更青睐它,而非 Anthropic 在 2025 年 11 月发布的最聪明模型 Claude Opus 4.5。
在 Claude Code 中,早期测试发现用户大约 70% 的时间偏好 Sonnet 4.6 而非 Sonnet 4.5。用户报告它在修改代码前能更有效地阅读上下文,并整合共享逻辑而非复制代码,使其在长时间使用中更不容易让人沮丧。
用户甚至在 59% 的时间里偏好 Sonnet 4.6 而非 Opus 4.5。他们认为 Sonnet 4.6 显著减少了过度工程和"偷懒"行为,在指令遵循方面明显更好,更少错误地声称成功,更少产生幻觉,并且在多步骤任务上有更一致的执行力。
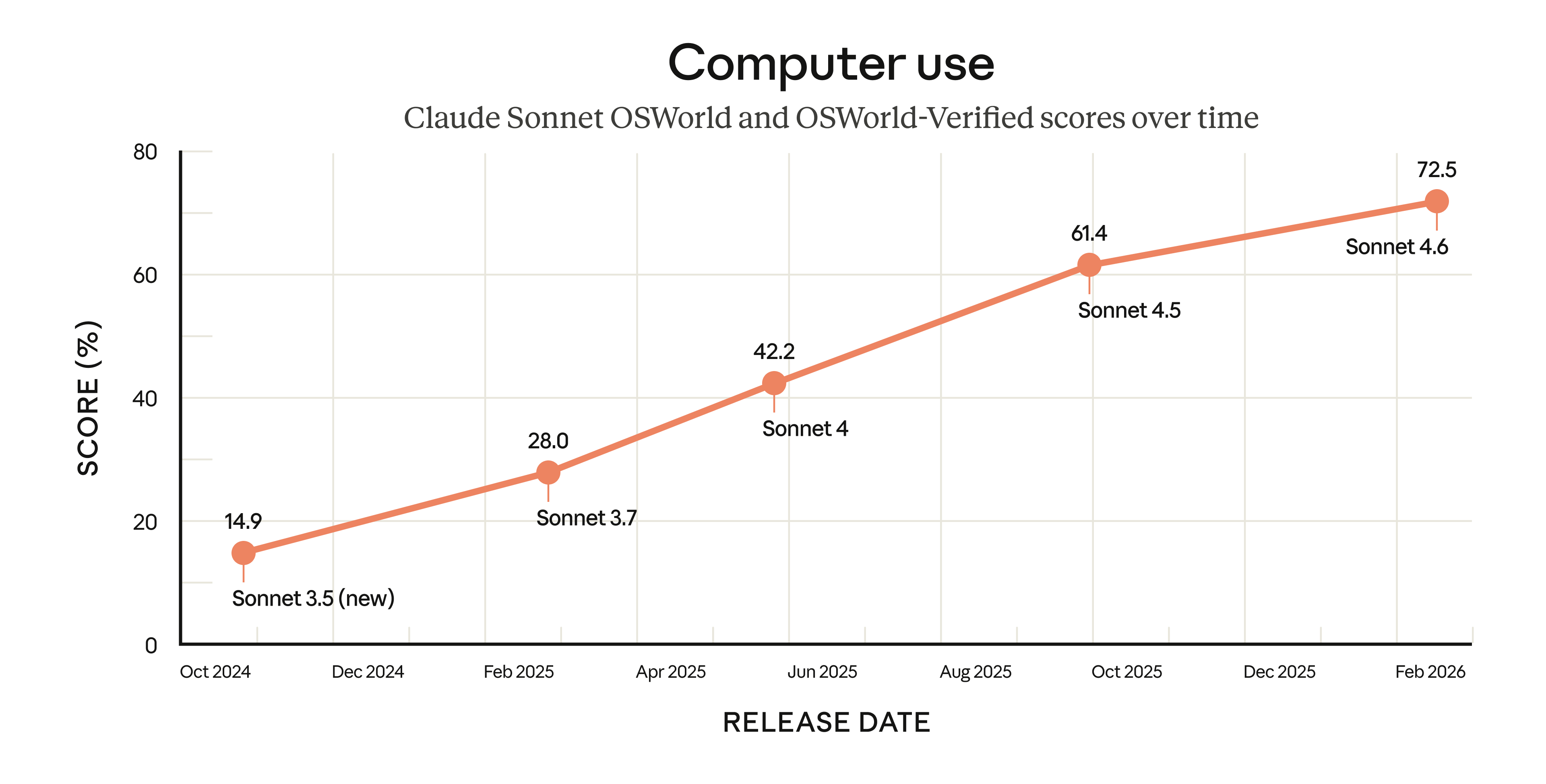
计算机使用能力飞跃
在 2024 年 10 月,Anthropic 是第一家发布通用计算机使用模型的公司,当时称其"仍然是实验性的——有时笨拙且容易出错"。
在 OSWorld 基准测试中(一个跨 Chrome、LibreOffice、VS Code 等真实软件的评估),十六个月间 Sonnet 模型取得了稳步进展。早期 Sonnet 4.6 用户在导航复杂电子表格或填写多步骤 Web 表单等任务中看到了接近人类水平的能力。
Anthropic 还在提高模型抵抗 prompt injection 攻击的能力——测试显示 Sonnet 4.6 比前代 Sonnet 4.5 有重大改进。
百万 Token 长上下文
Sonnet 4.6 的 100 万 token 上下文窗口足以在单次请求中容纳整个代码库、冗长的合同或数十篇研究论文。更重要的是,Sonnet 4.6 能在所有这些上下文中有效推理。
这在 Vending-Bench Arena 评估中体现得尤为清晰——该测试评估模型运营模拟企业的能力。Sonnet 4.6 开发了一种有趣的策略:在前十个模拟月大量投资产能,花费明显超过竞争对手,然后在最后阶段急转弯聚焦盈利能力。这个时机帮助它远远领先于竞争对手。
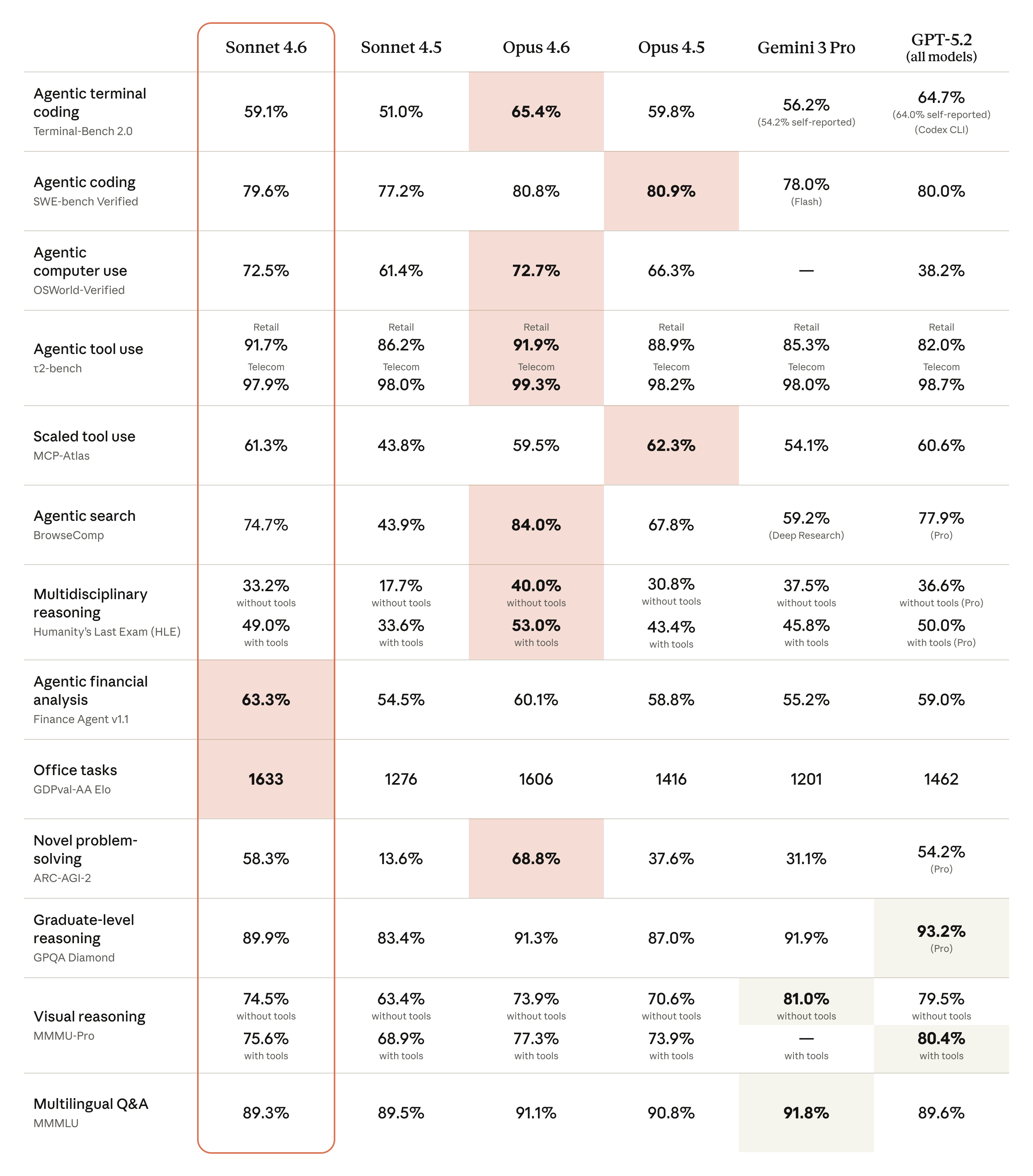
企业客户评价
多家企业对 Sonnet 4.6 给予了高度评价:
- 编码领域:在复杂代码修复方面表现出色,在大型代码库搜索中尤为突出
- 企业文档:在 OfficeQA 上匹配 Opus 4.6 的性能,显著提升文档理解能力
- 计算机使用:在保险基准测试中达到 94% 的准确率,成为测试过的最高性能模型
- 前端设计:拥有"完美的设计品味",比以往任何测试过的模型都需要更少的手动调整
- iOS 开发:产出了"测试过的最佳 iOS 代码",具有更好的规范遵从性和架构设计
平台更新
Sonnet 4.6 支持标准模式和扩展思考(Extended Thinking),以及 beta 版的上下文压缩功能。搜索工具现在会自动编写并执行代码来过滤和处理搜索结果。程序化工具调用(Programmatic Tool Calling)现已正式可用。
Sonnet 4.6 现已在所有 Claude 平台、API 和主要云平台上可用。免费版本也已默认升级到 Sonnet 4.6。
编辑点评
Sonnet 4.6 的发布是一次"以下克上"的经典案例。当一个更便宜、更快的模型在多数场景下击败了自家最顶级的旗舰模型(Opus 4.5),这不仅是技术进步,更是商业模式的颠覆。70% 的用户偏好率和 59% 对 Opus 的胜率,意味着大多数用户不再需要为最贵的模型付费。更值得关注的是计算机使用能力的进步——从"笨拙且容易出错"到在真实软件上稳步逼近人类水平,这个方向比单纯的 benchmark 刷分更具变革意义。Sonnet 4.6 或许标志着 AI 助手从"对话伙伴"向"数字员工"转变的关键拐点。


